Address specific performance scenario where understanding the technical details will be helpful for the folks that don't spend much time thinking about database indexes (don't worry not you)
Everybody knows that software performance is a super important thing. It affects how (and if) people use your software, it's cost to operate, it can be the difference between working and not working.
But programmers are going to program, and programmers love optimizing, even when it's not important for the outcome of the software. This phenomena is enough of a thing that computer scientist god Donald Knuth has said "Premature optimization is the root of all evil*"
Thankfully performance is quantifiable using something called Big O notation
* probably this is true
There are three important categories of performance, which are based on the relationship between performance and data size - fast, regular, and morally repugnant.
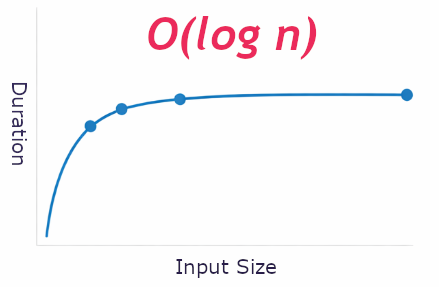
As the size of your input N increase, your performance Y will either remain constant, or degrade slowly. In this case your performance will degrade much slower than the increase of data size.
This is BigO of O(logn)
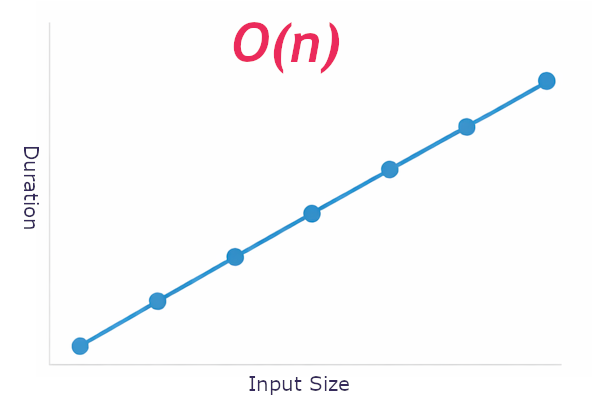
As the size of input N increases, your code will take a similar amount of time to process. So processing 10mb will take about twice as long as 5mb.
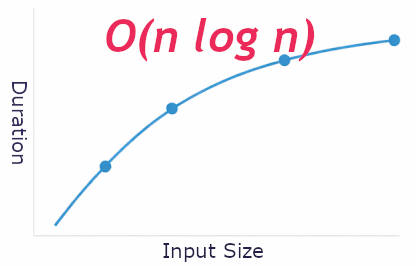
Referred to as O(n) (linear) or O(nlogn) (quasilinear)
In this case, your processing time will grow much faster than your input, eventually the performance degrades to 0.
Example Processing 10mb will take 5x as long as 5mb, and processing 20mb will take 5,000x as long.
This is written as O(n²)

Relational database generally use binary trees (indexes) to look up data in logarithmic time, lookups are O(logn), and joins are O(nlogn). So for every record N you want joined, processing increases time by log(n).
Sometimes they use hash tables, which are even better as far as performance, but we'll save that for another time.
A binary tree is a way of storing/ordering records so that each record contains a link to two more records, one ordered before and one after.
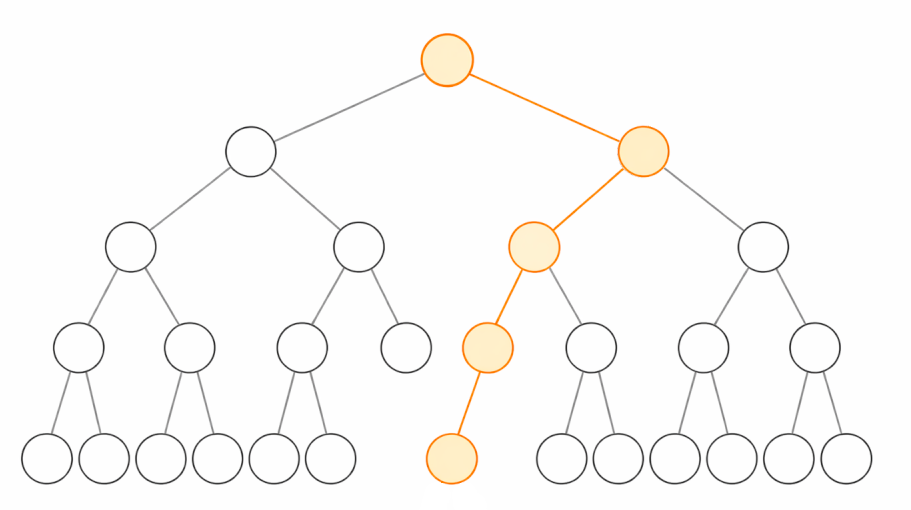
In the chart above you can see that the longest possible path to a node would equal the height of the tree.
And you can imagine that adding more and more records will NOT increase the height of the tree very quickly.
The number of records available is calculated by height N is 2ⁿ, so you can find your record in a pile of 1,125,899,906,842,624 records with just 50 checks (at worst)
Imagine you have a "Person" table with a Person ID field, and Cats table with an Person ID that represents the cat's owner.
If you have 1 million people, and 7 million cats, that's 7,000,000,000,000 (trillion) possible People-Cat relationships. 7 trillion isn't really a big number if you're the federal government, but if you're a happy little Postgres database, it's huge.
But because your database sorted their Cats into a binary tree ordered by Owner ID, it only needs to check ~16M relationships to tell you exactly who owns each of the 7 million cats.
This is why it's important to have your database tuned with the correct indexes and relationships. 7T is about a 500,000 times bigger than 16M and will take that much more time to process.
In a world of non-relational databases, or clunky ORMs (they're all clunky), or just plain ig-nernt, you'll come across situation where code is being used to process data. Simple loops are simple, but they lack indexes so you're stuck with the 7T cat owner relationships.
This is bad.
Schema defines your architecture, it's important that you start with schema when designing software.
Code is easy to change, schema is not.